Carl von Clausewitz painted by Karl Wilhelm Wach. Credit Wikipedia. Click to enlarge.
Carl von Clausewitz in his On War wrote, “War is the realm of uncertainty; three quarters of the factors on which action in war is based are wrapped in a fog of greater or lesser uncertainty. A sensitive and discriminating judgment is called for; a skilled intelligence to scent out the truth.” Though Clausewitz never specifically wrote the phrase ‘Fog of War’, the above quote is the source of the term which we abbreviate today as FoW. FoW in the 18th and 19th centuries (the era specifically covered by General Staff: Black Powder) was especially problematic because of the lack of modern day battlefield information gathering techniques such as drones, aircraft and satellites (yes, hot air balloons were used in the Civil War but their actual value during combat was minimal).
General Staff is a wargame that can simulate the FoW experienced by an 18th or 19th century commander and his staff. We use the qualifier ‘can simulate’ because General Staff can run in five different ‘modes’:
- Game mode / No Fog of War
- Game mode / Partial Fog of War
- Simulation mode / No Fog of War
- Simulation mode / Partial Fog of War
- Simulation mode / Complete Fog of War
Game mode came from a strong desire to create an introductory wargame, with simplified rules, played on historical accurate battlefield maps that could be used to introduce novices to wargaming.
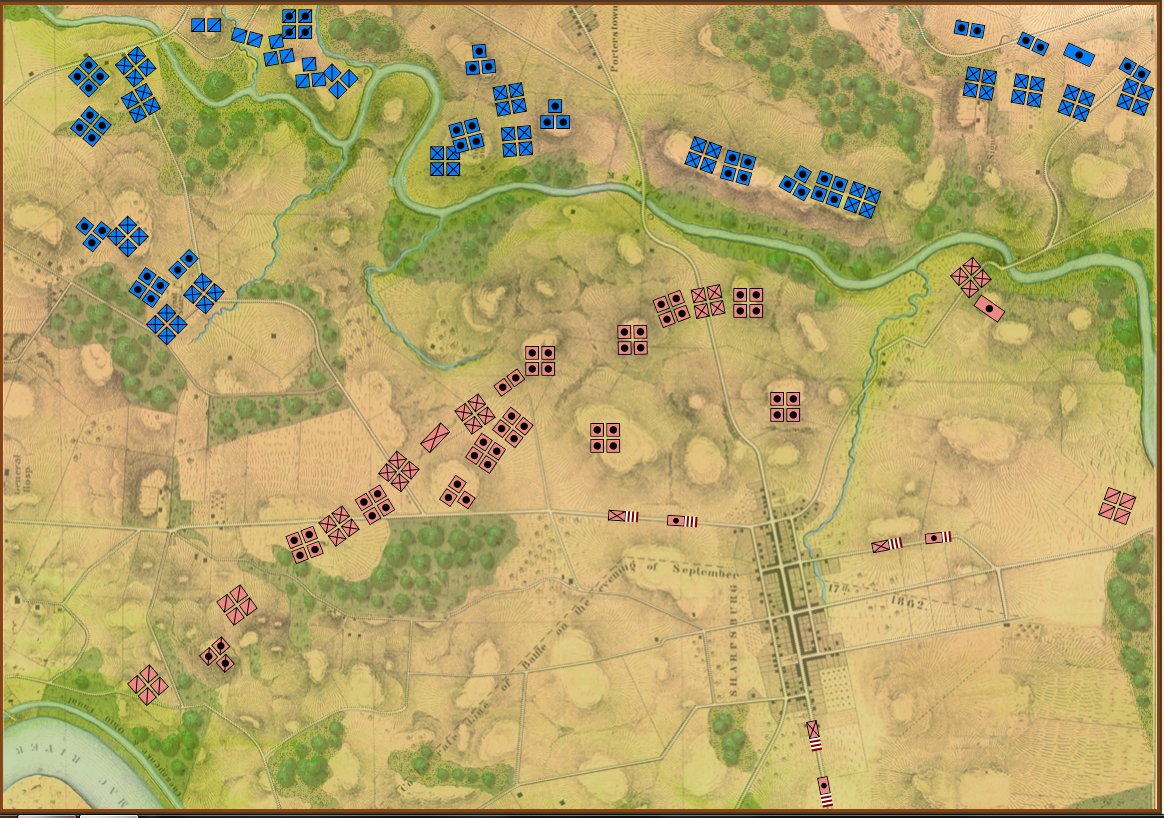
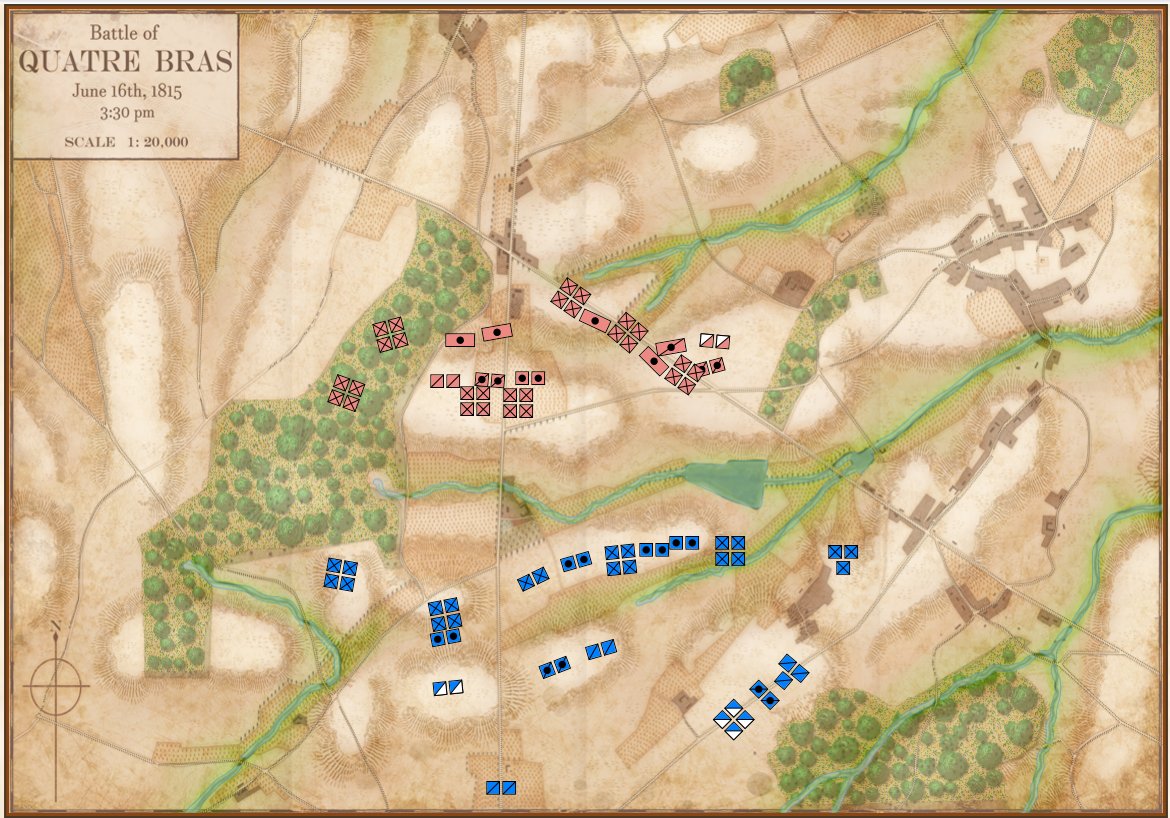
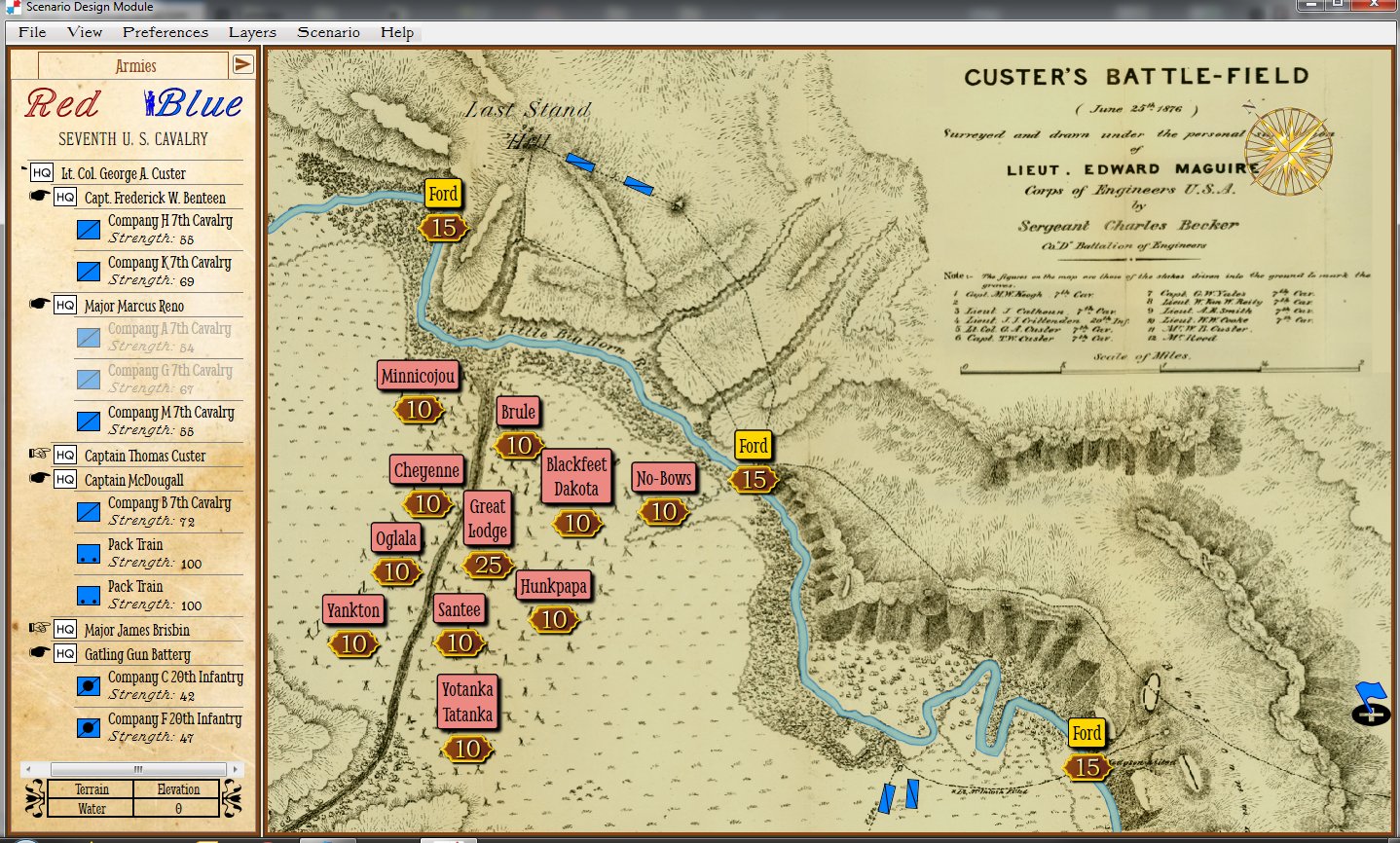
1st Bull Run, 11:30 AM, Simulation Mode, No Fog of War. Reinforcements shown. Click to enlarge.
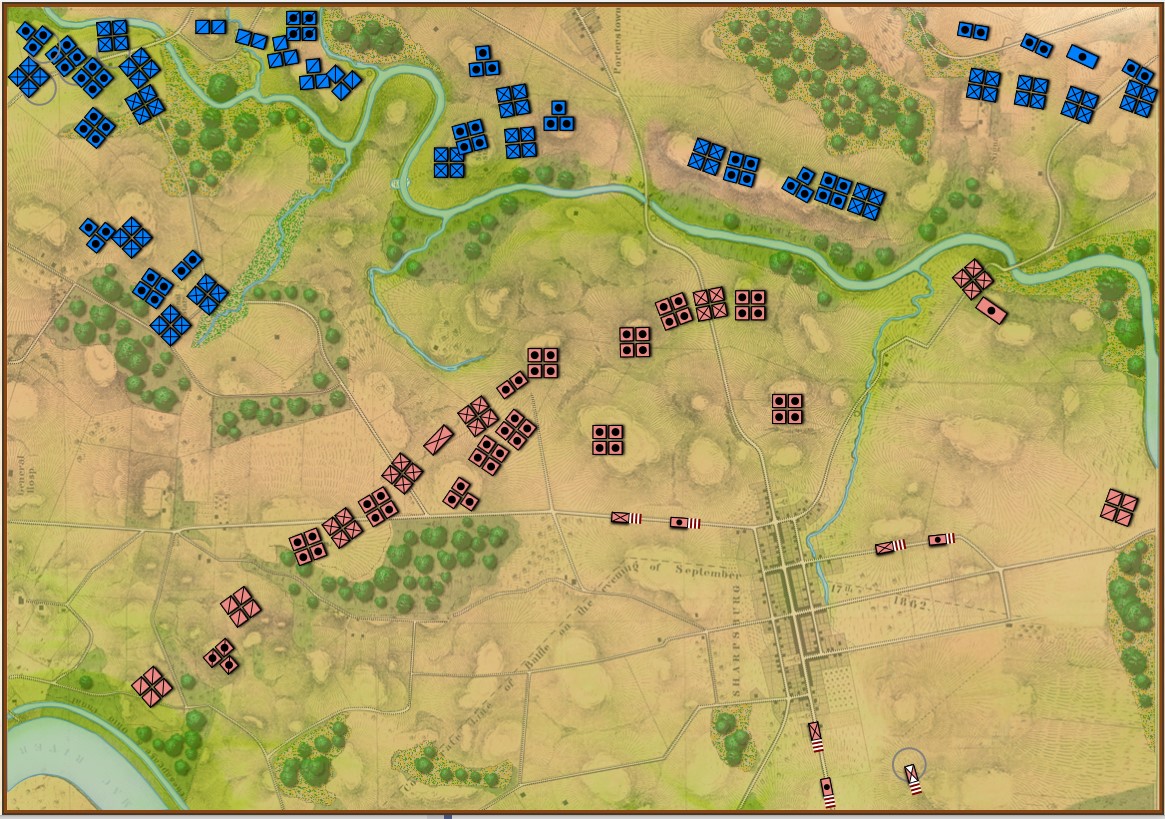
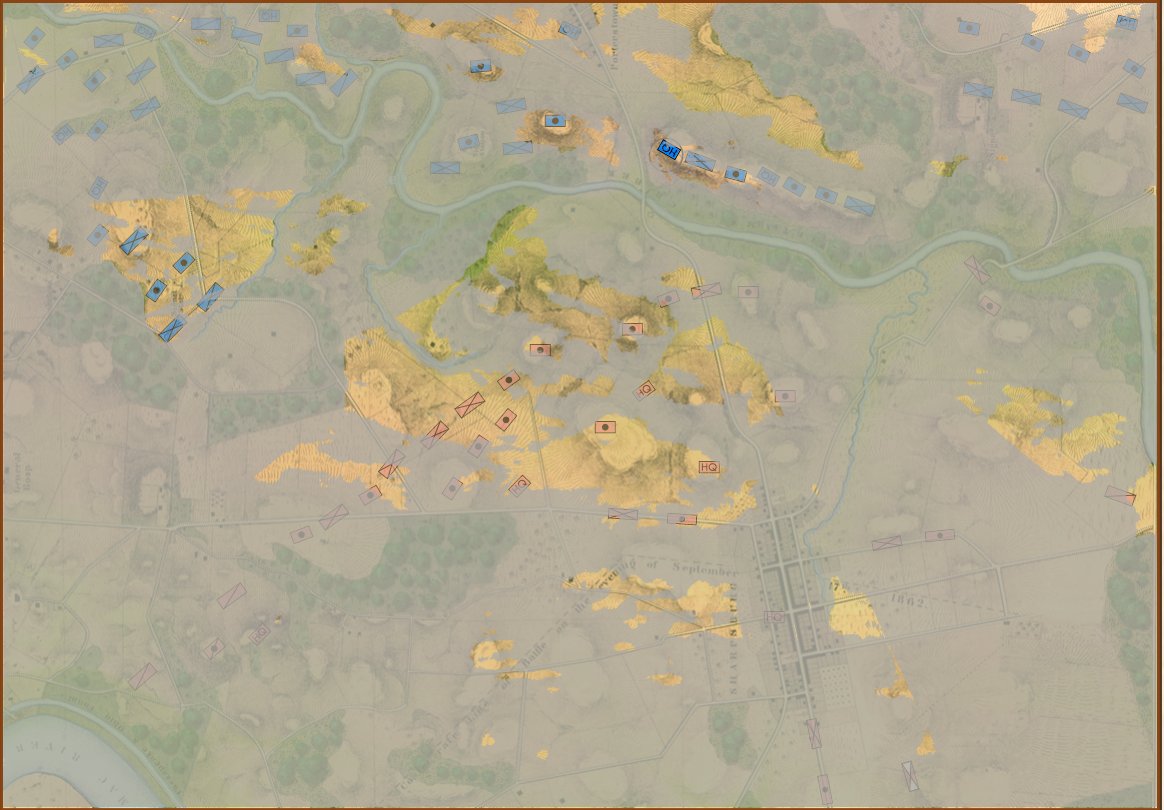
Antietam, 0600, Game Mode. Reinforcements shown. Click to enlarge.
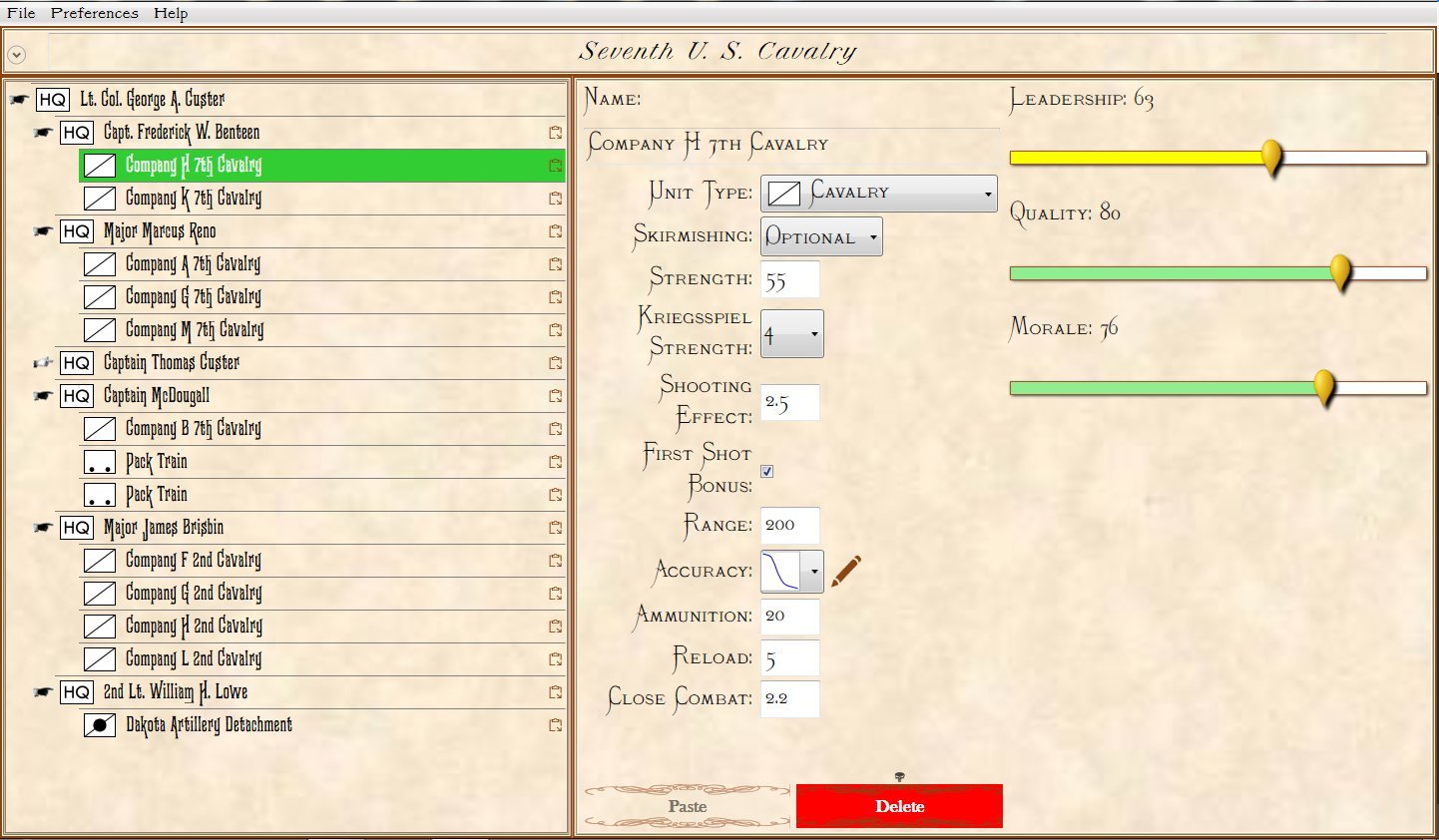
In the above two screen shots from General Staff you can clearly see the differences between Simulation and Game mode. In Simulation mode a unit’s exact strength in men, leadership value, morale value, experience value, number of volleys and the time it will take for a courier to travel from it’s commander’s HQ to the unit are displayed and tracked. In Game Mode, unit strength is represented by the number of icons (1 – 4) and leadership, morale, experience, and ammunition are not tracked. Units are moved directly by the player and there are no HQ units. In Simulation Mode, orders are given from the commanding HQ down to the subordinate commander’s HQ and then to the actual unit. The leadership value of each HQ effects how long the orders will be delayed on the way.
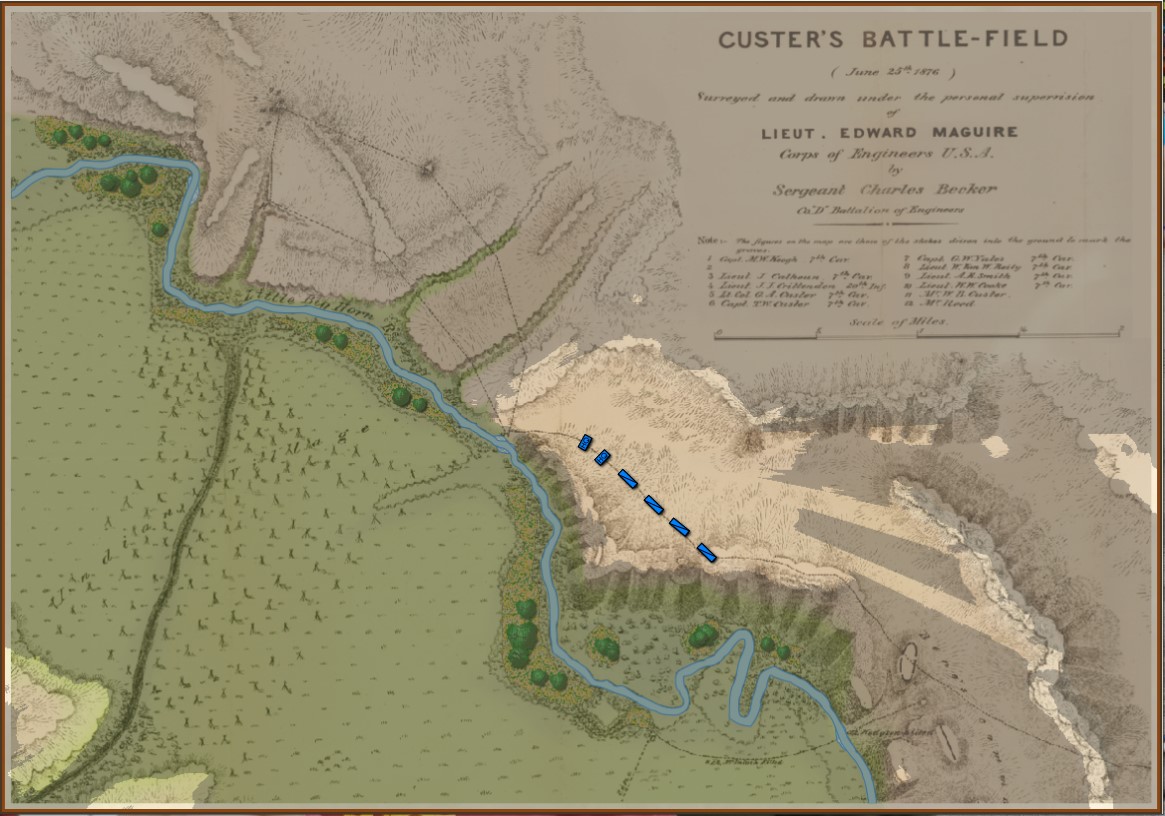
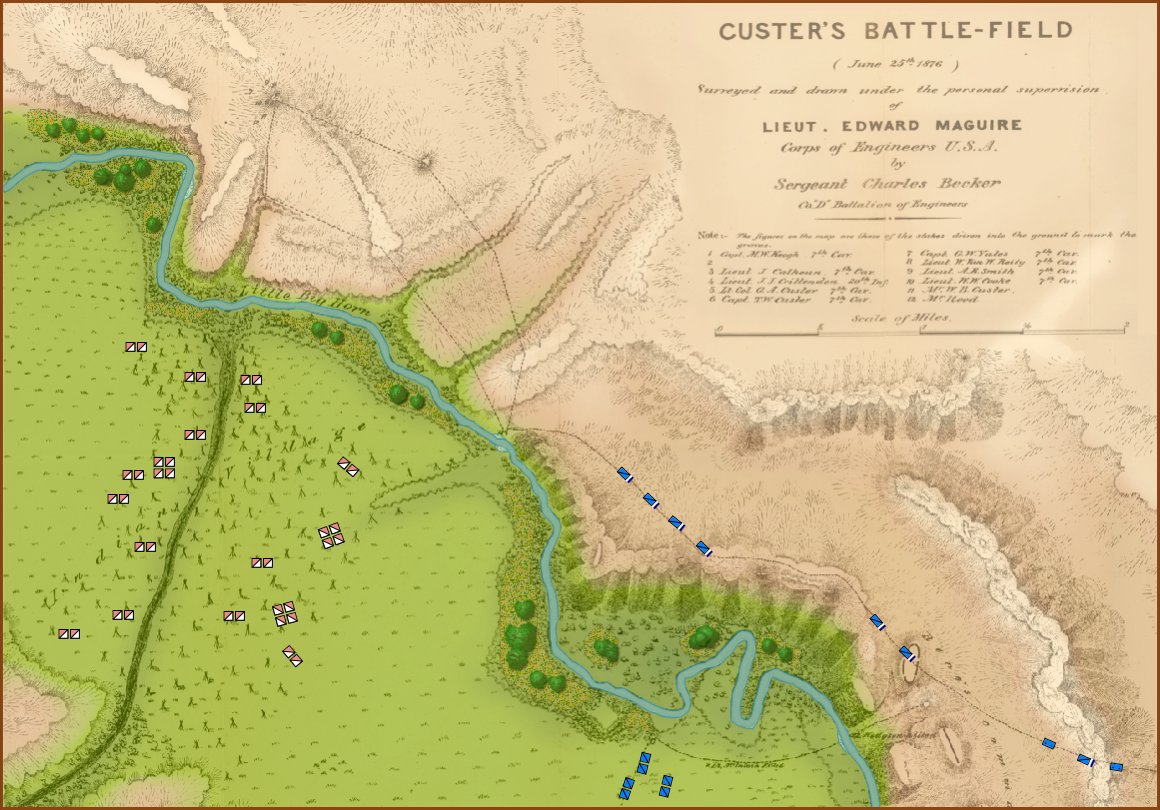
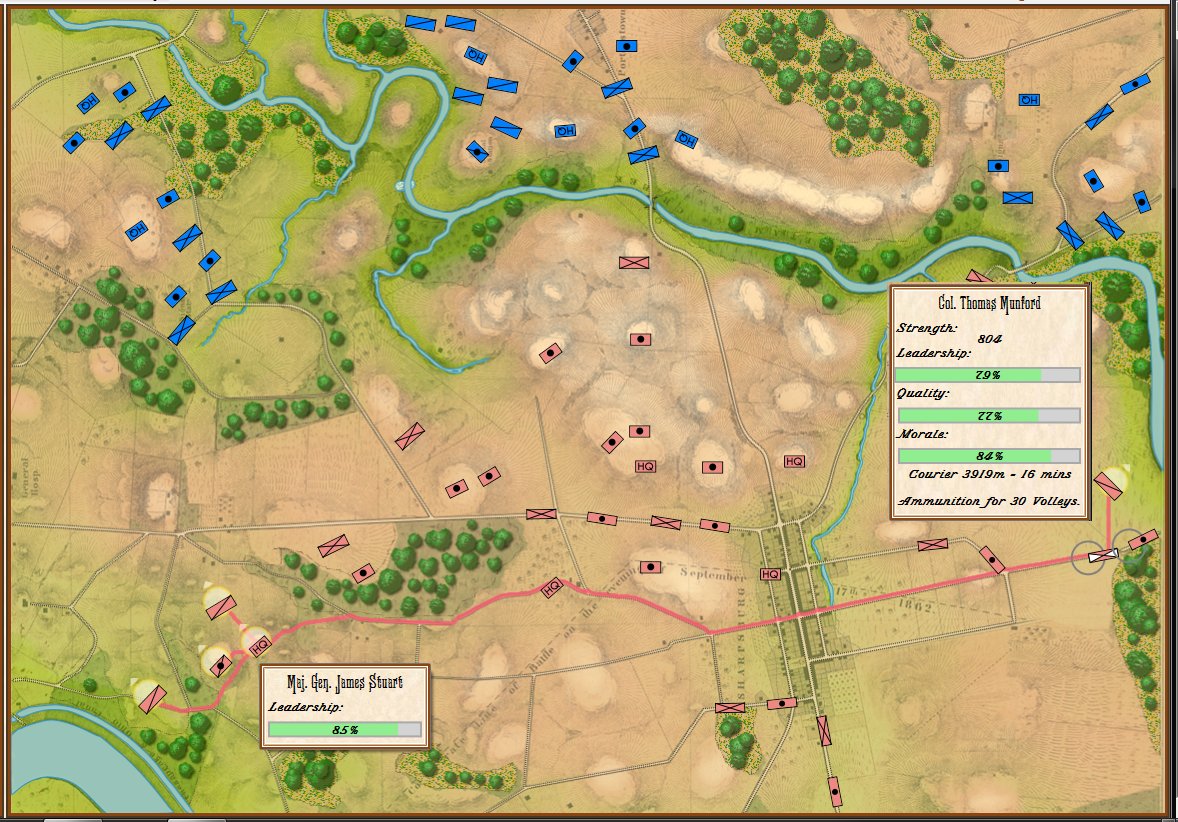
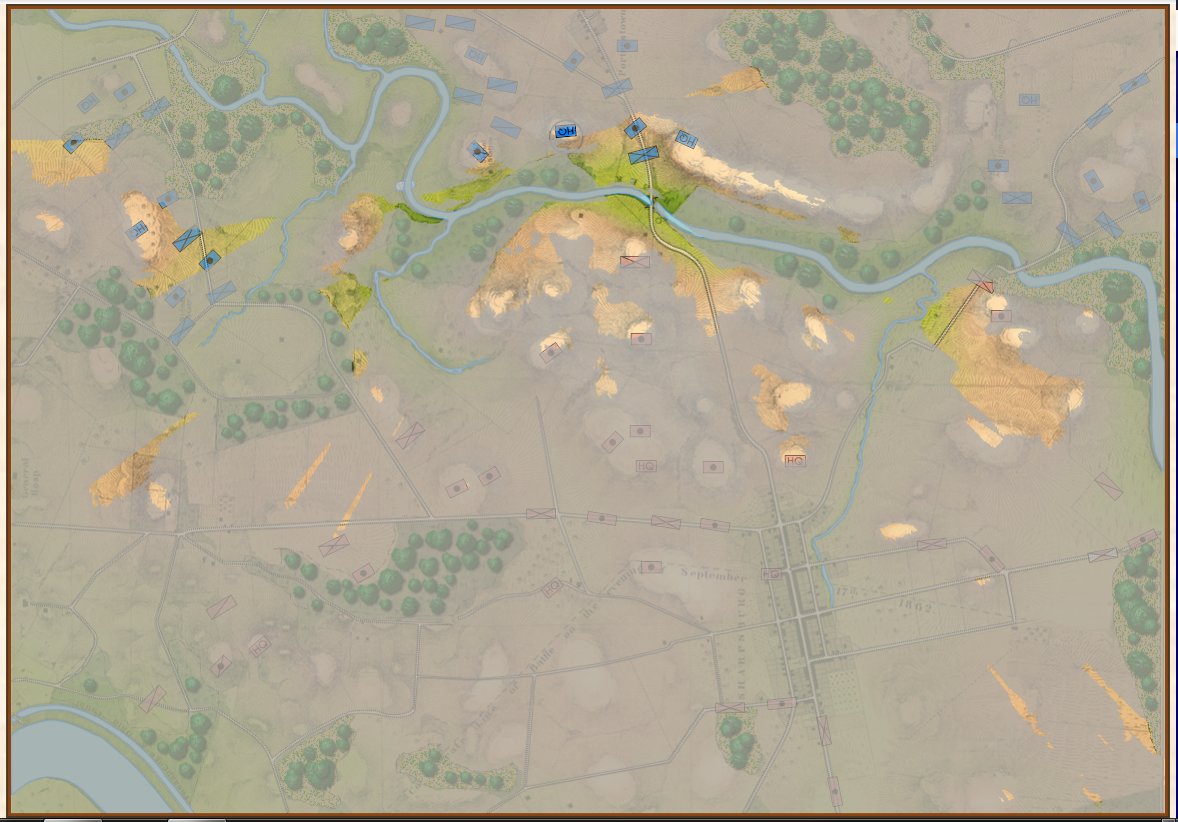
Little Bighorn, Simulation Mode, Complete Fog of War (from the commander’s perspective). Screen shot. Click to enlarge.
In the above screen shot, we see ‘Complete Fog of War’; only what the commander can see of the battlefield is displayed. In this case, this is what Colonel George Custer could see at this time. Just as in real life, in Complete Fog of War the commander receives dispatches from his troops about what they have observed; but this information is often stale and outdated by the time it arrives.
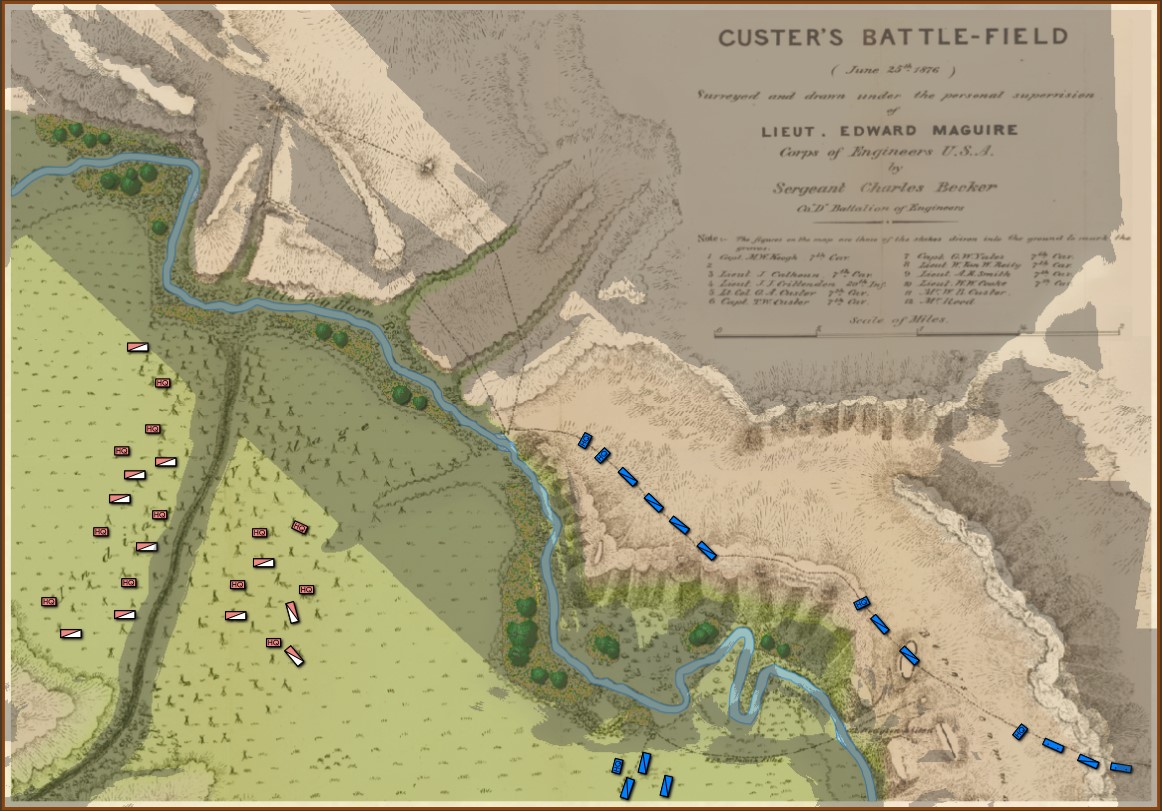
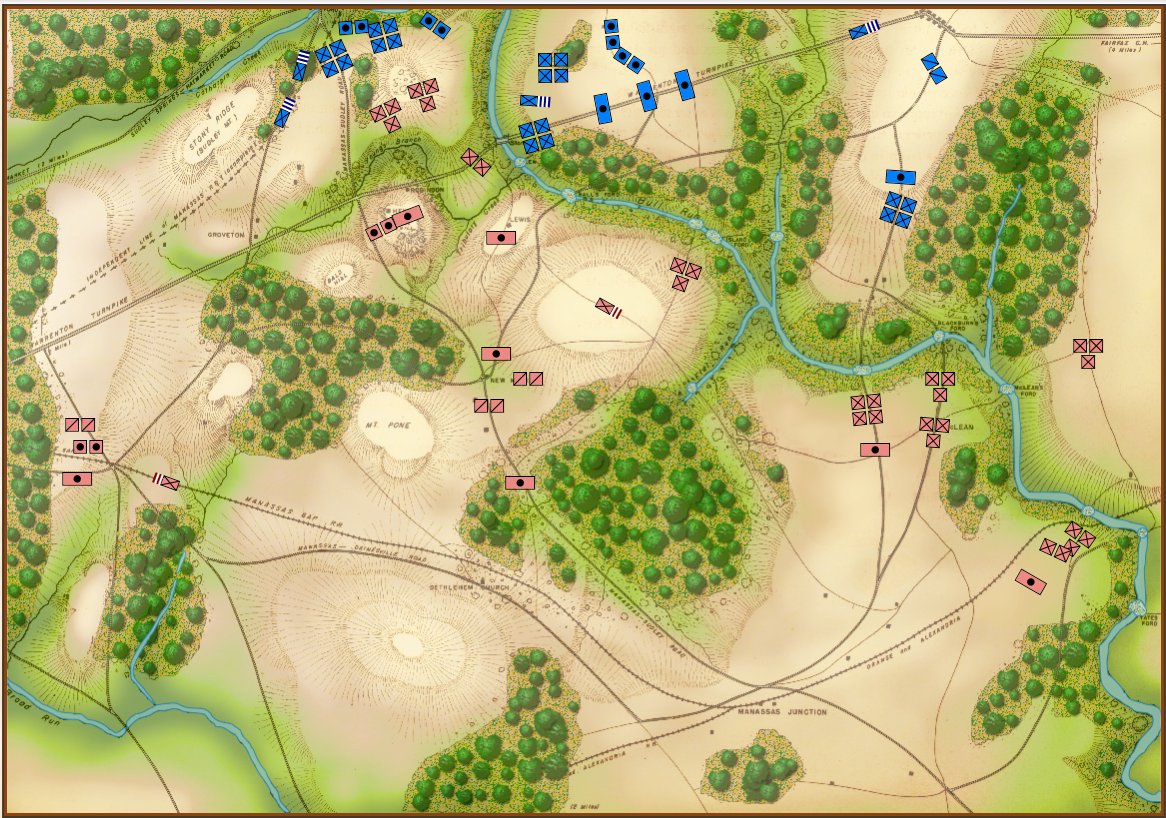
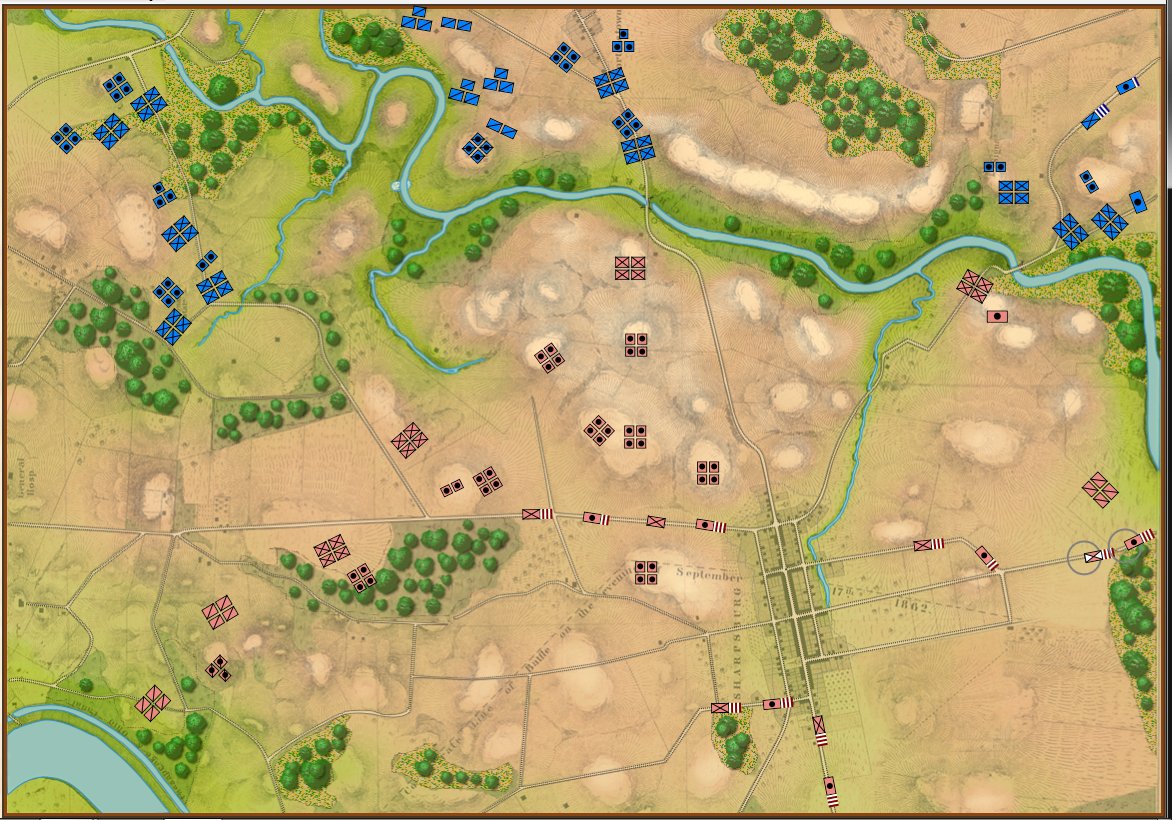
Little Bighorn, Simulation Mode, Partial Fog of War. This displays what all Blue forces can observe. Click to enlarge.
In the above screen shot Partial Fog of War is displayed. This is the sum of what is observable by all units (in this case, the Blue force). This is historically inaccurate for the 19th century and is included as an option because, frankly, users may want it and, programmatically, it was an easy feature to add. Throughout the development of General Staff we have consistently offered the users every conceivable option we can think of. That is also why we have included the option of, “No Fog o War,” with every unit visible on the battlefield. It’s an option and some users may want it.
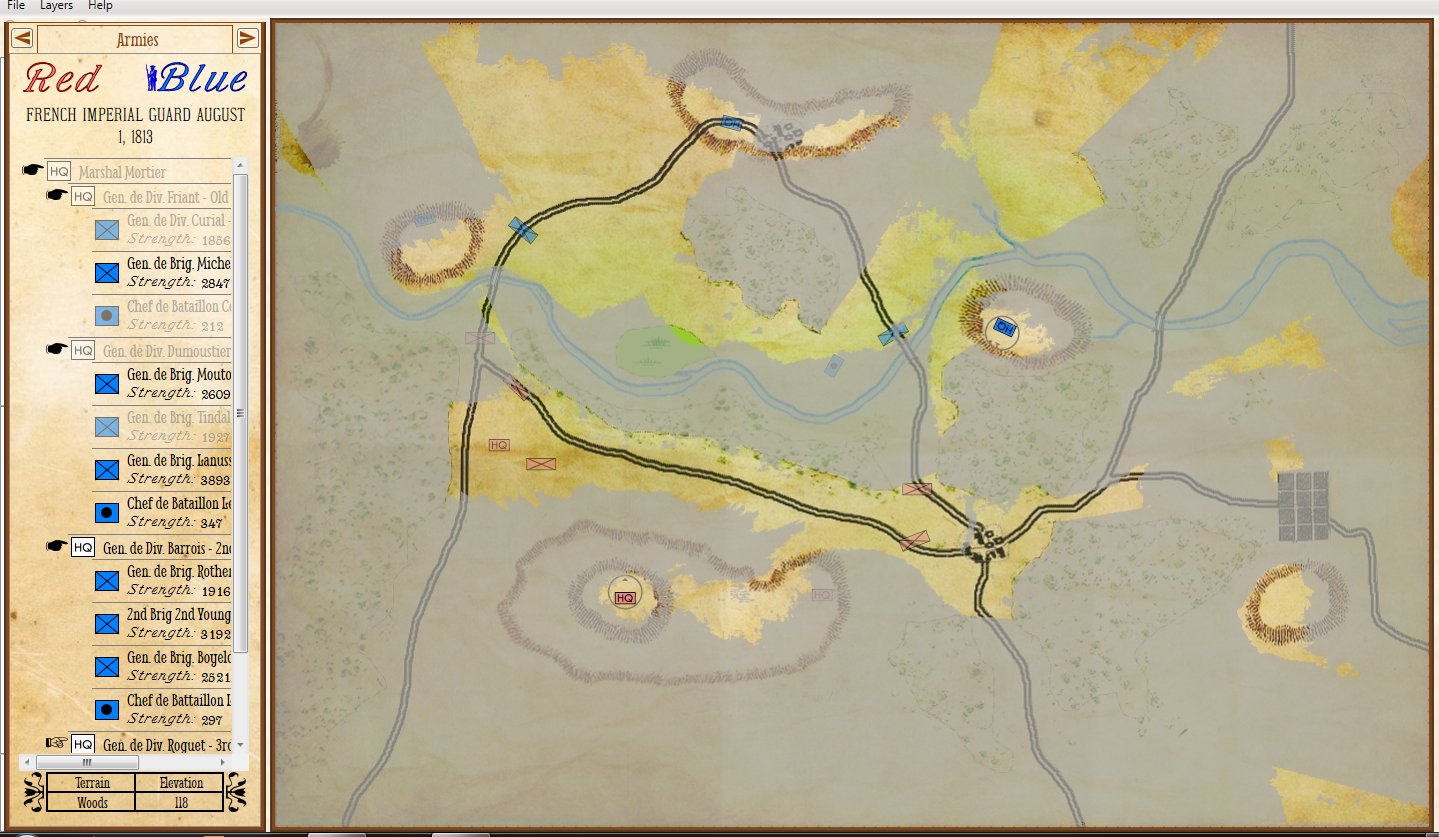
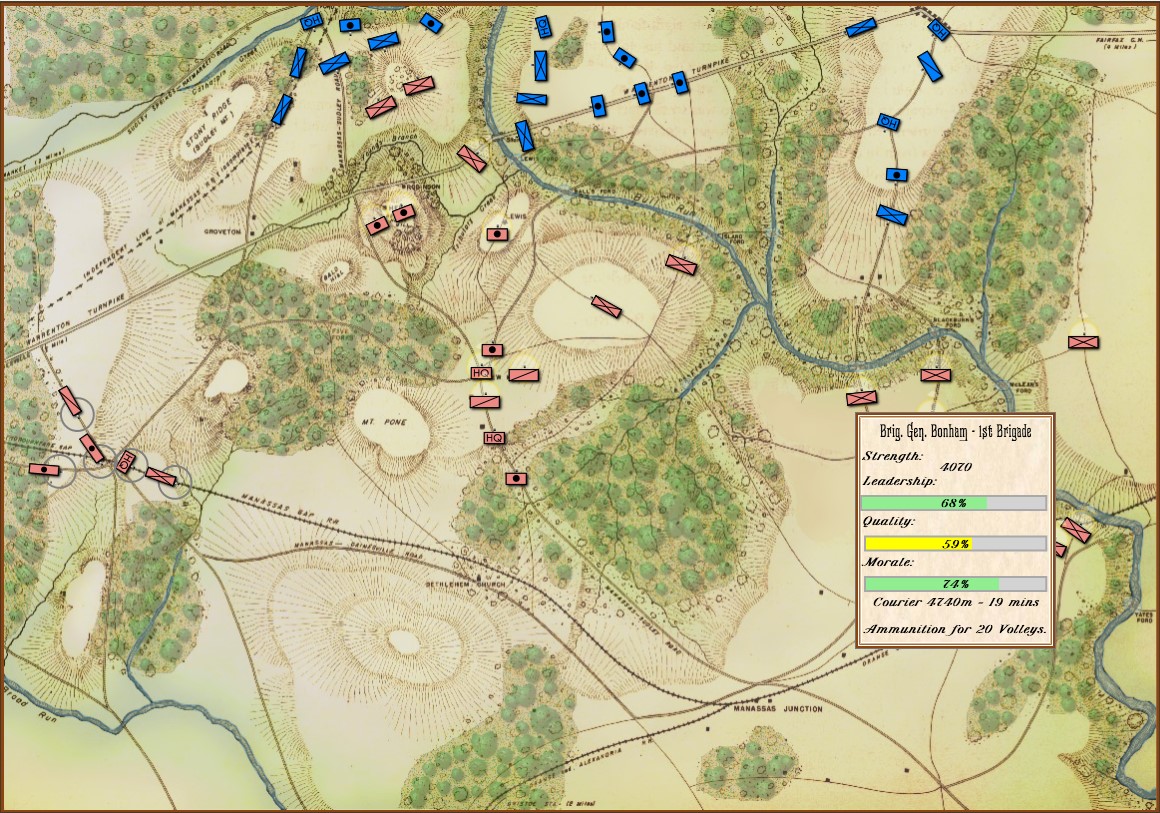
We have experimented with different ways of displaying ‘stale’ unit information including this method, below:
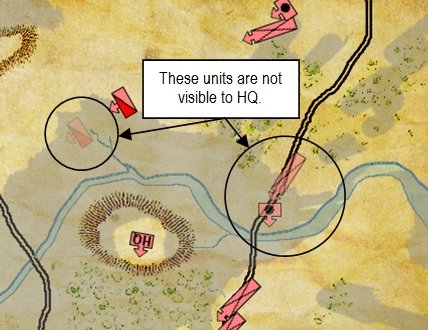
An example of how units that are not directly visible to HQ are displayed. The longer that a unit remains unobserved, the fainter it becomes. (Click to enlarge.)
We are now experimenting with overlays.
As always, your questions and comments are appreciated. Please feel free to email me directly.