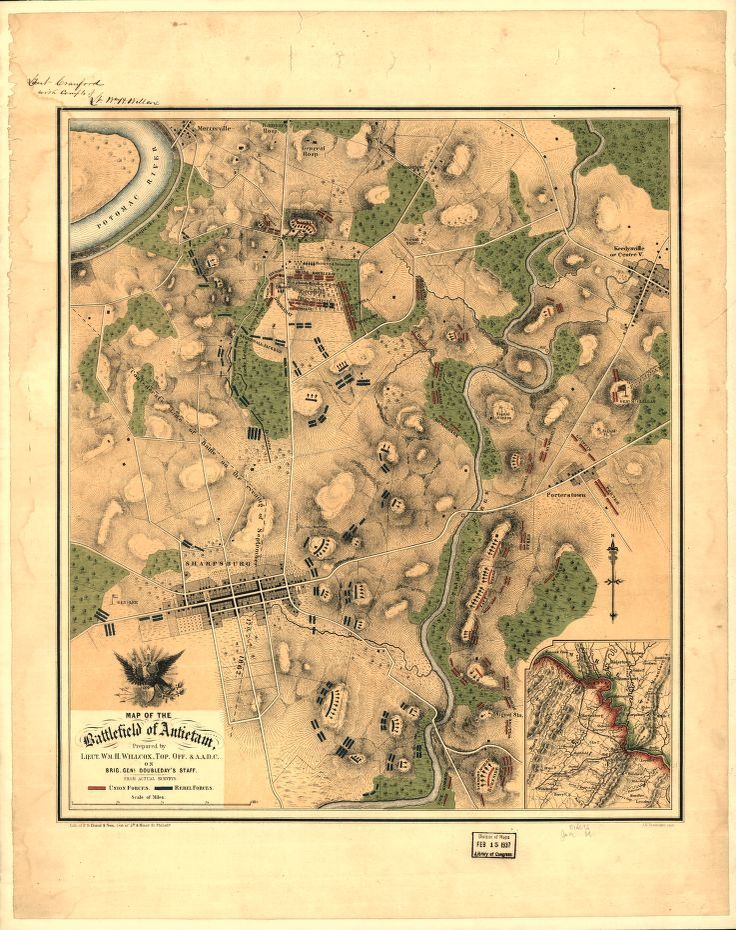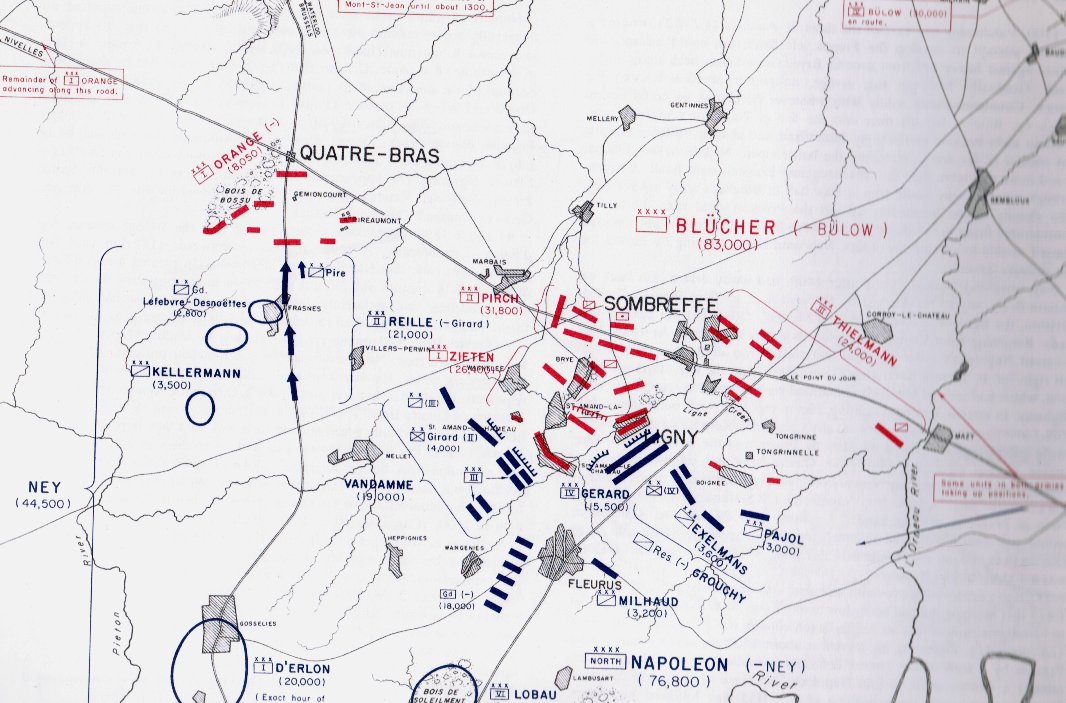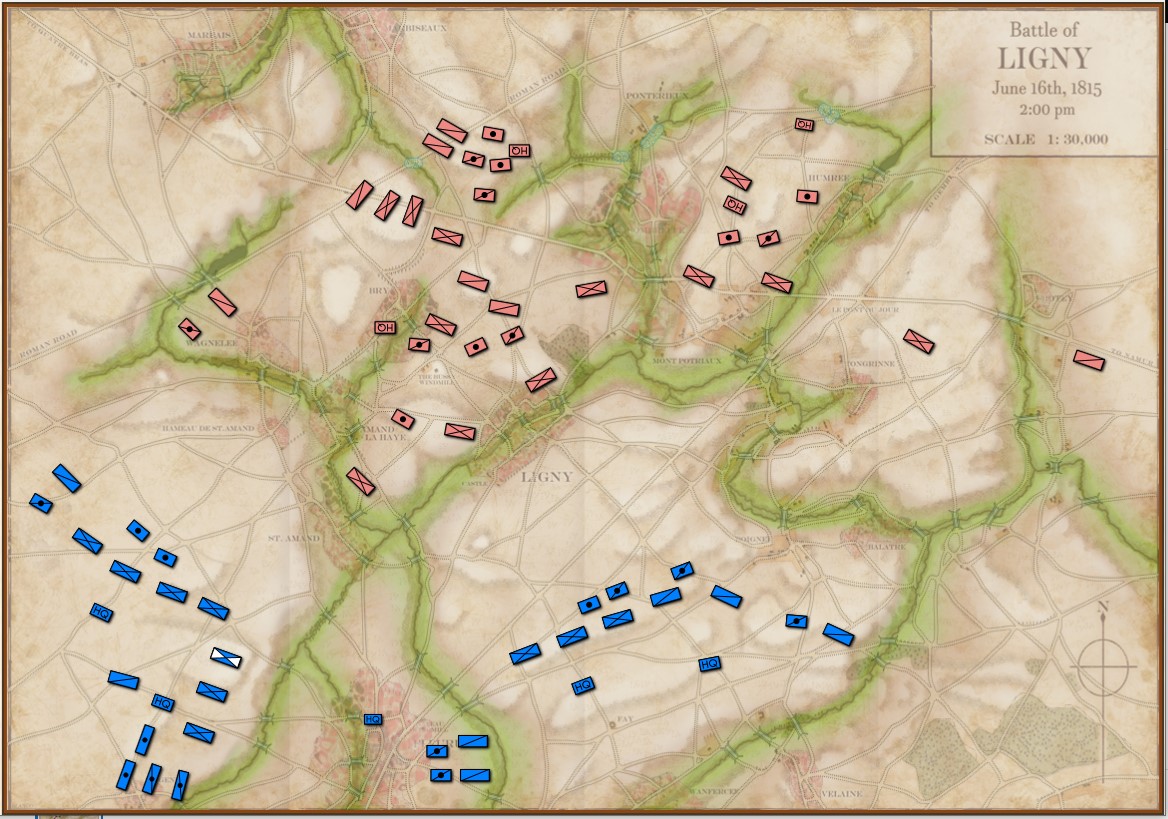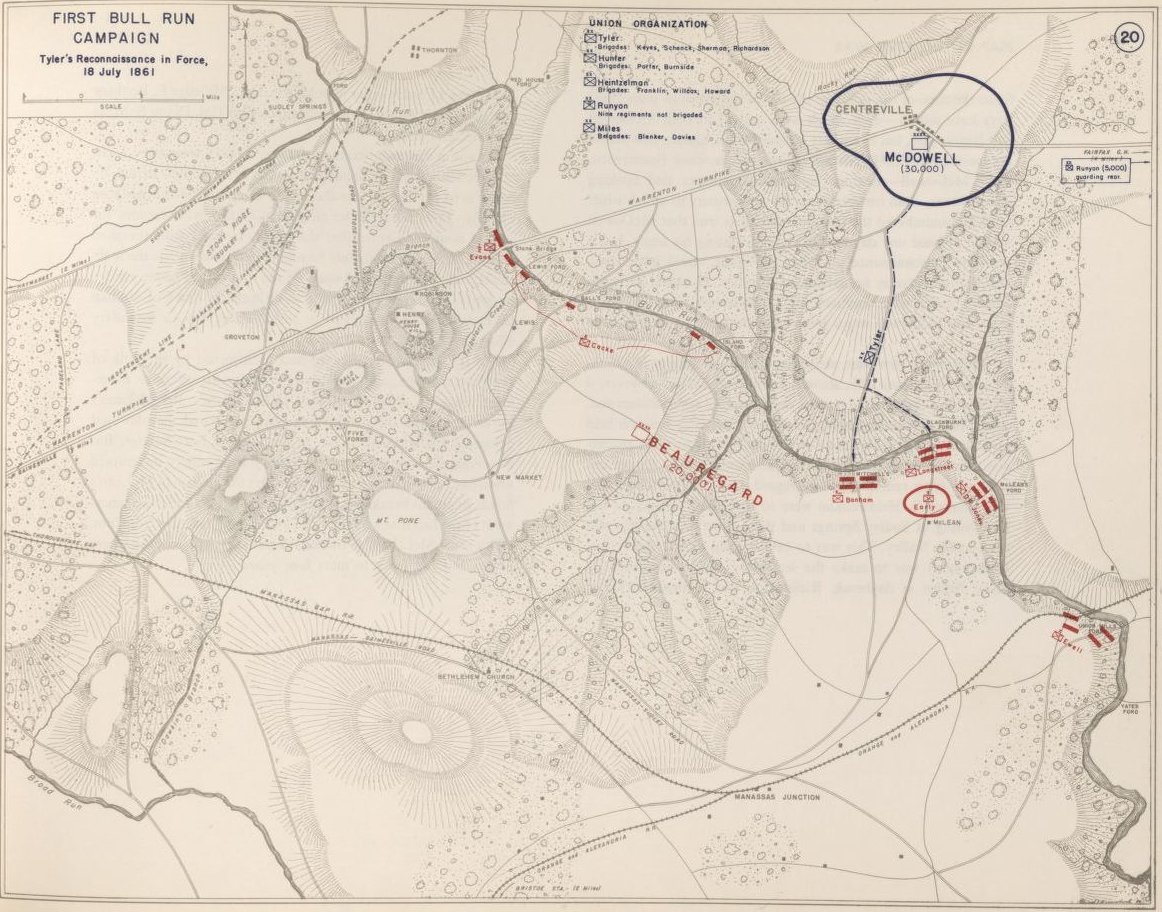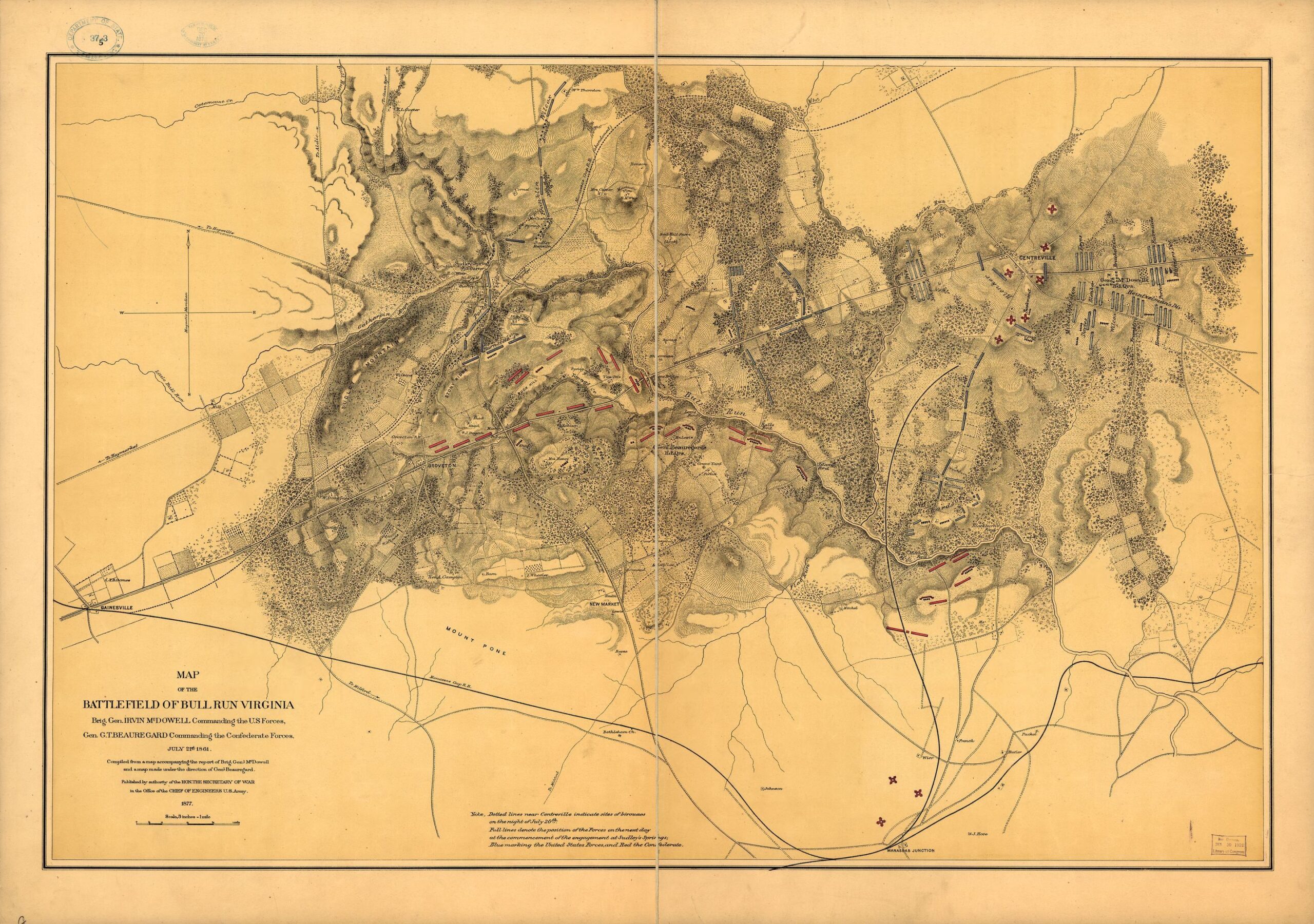
Quatre Bras, June 16, 1815. Click to enlarge
Napoleon has humbugged me, by God!” Lord Wellington swore. “He has gained twenty-four hours’ march on me!” 1)David Chandler, Waterloo: The Hundred Days, Macmillan Publishing Co., Inc. New York 1980, p. 85 And, indeed, he had.
The Armée du Nord, racing north on the roadnet from Paris to Brussels, now occupied the crucial strategic ‘central position’ between the Anglo-Allied army under Wellington assembling at Quatre Bras in the west, and the Prussian army under Blücher at Ligny in the east. Napoleon, outnumbered by the combined forces of Wellington and Blücher only had one realistic option: destroy his opponent’s armies separately before they could combine and destroy him.
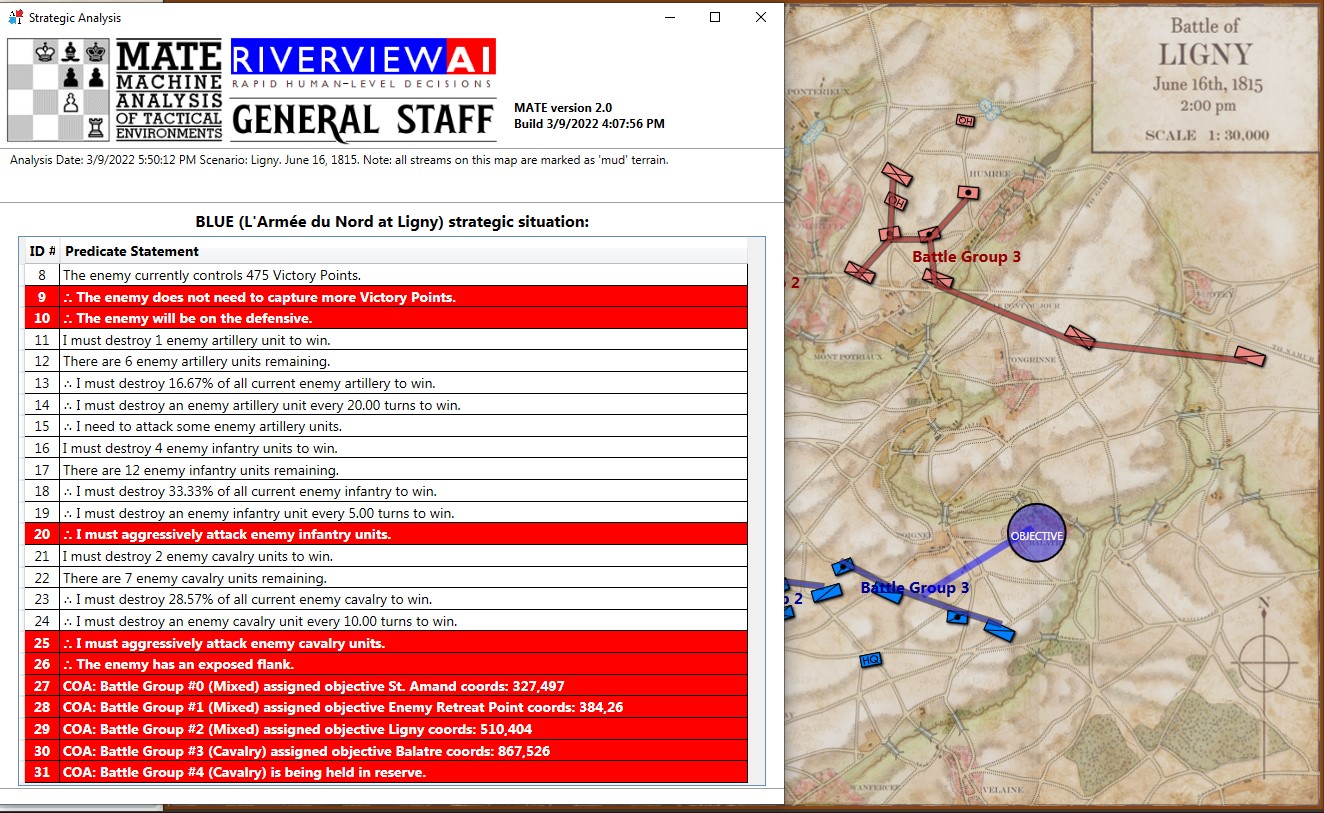
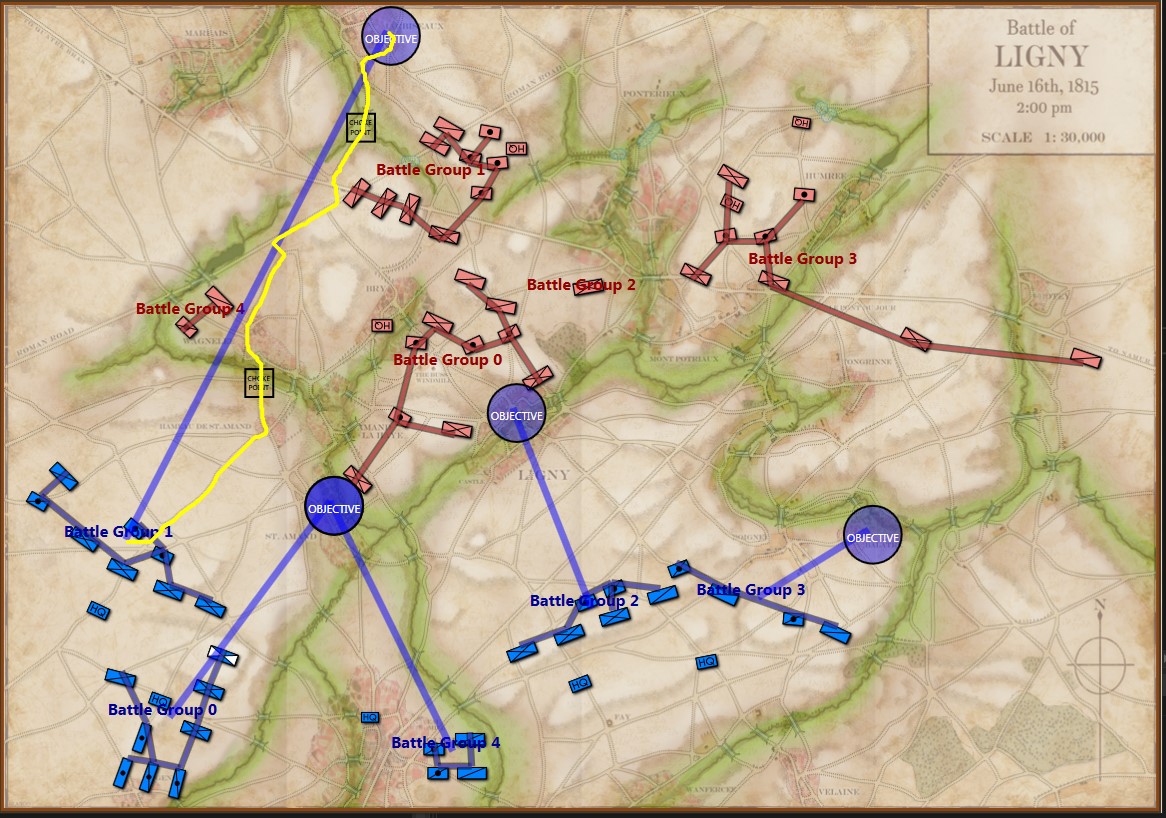
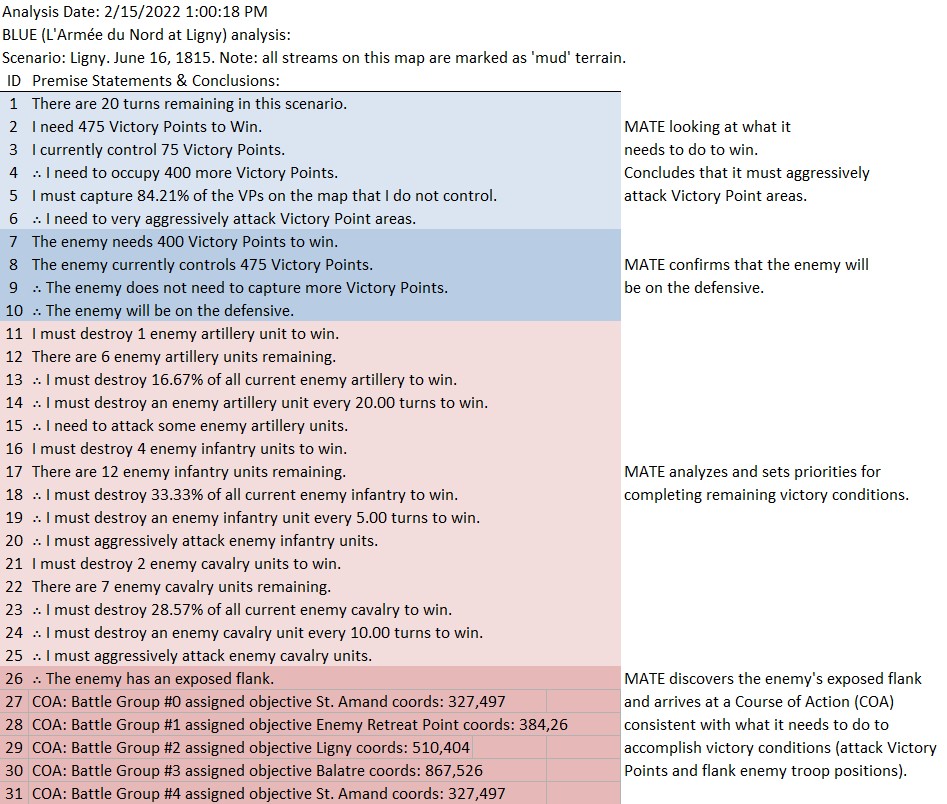
Napoleon divided the Armée du Nord into two wings (the left commanded by Marshal Ney and the right by the Emperor, himself). The Imperial Guard would serve as the strategic reserve. In our previous blog, we showed the MATE (Machine Analysis of Tactical Environments) artificial intelligence analysis of the battle of Ligny.
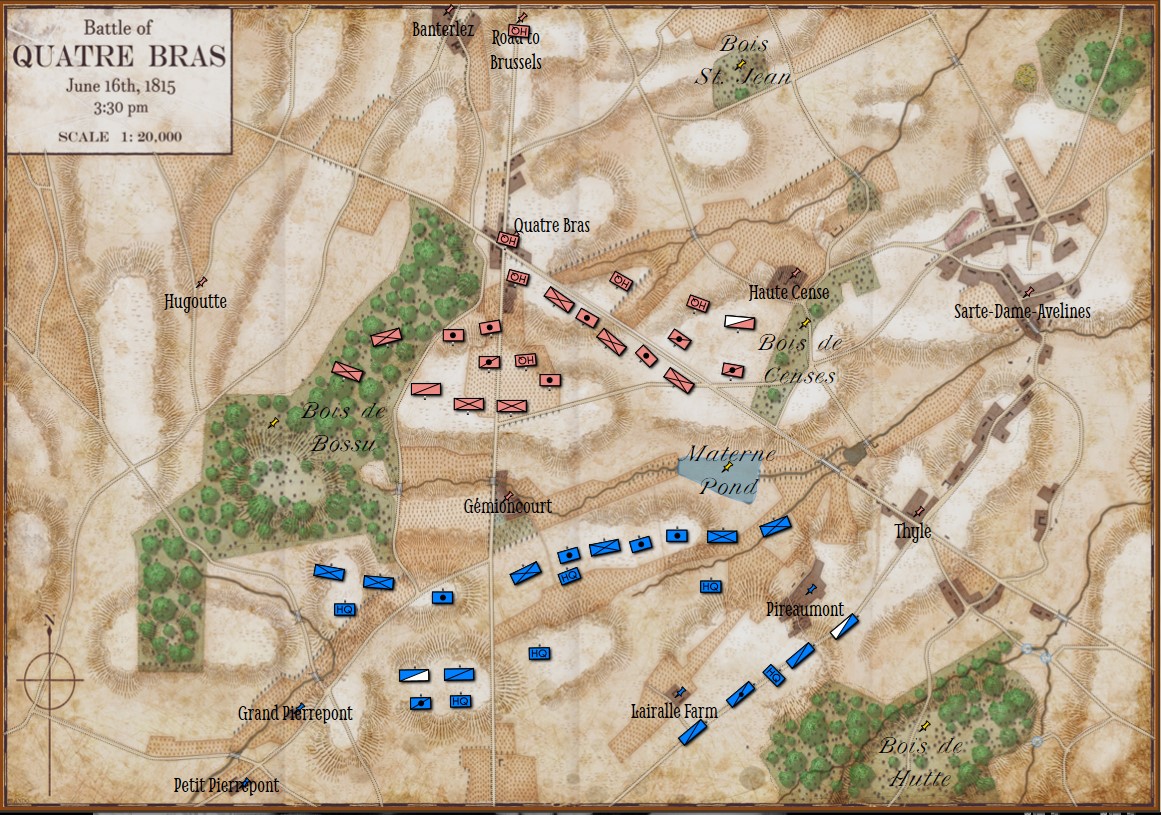
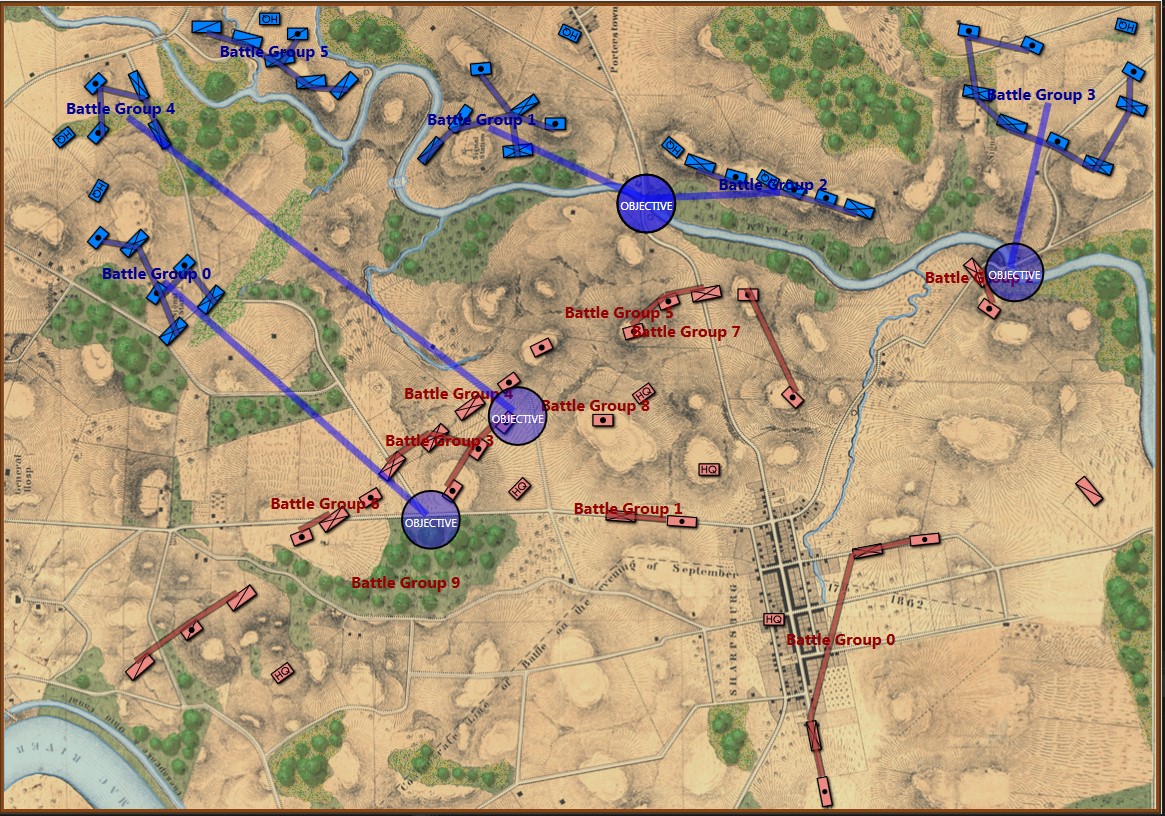
The starting positions of the Armée du Nord (Blue) and the Anglo-Allied Army (Red) at the battle of Quatre Bras. Screen shot from General Staff: Black Powder. Click to enlarge.
The positions in the above screen shot come from the West Point Atlas of the Napoleonic Wars and Chandler’s Waterloo: The Hundred Days. I’ve ordered Mike Robinson’s The Battle of Quatre Bras, 1815 (which is very highly regarded) but it’s coming from Europe and will be a while before it arrives. I’ll update the positions accordingly when it arrives.
Today MATE is going to show off a new trick that it learned.
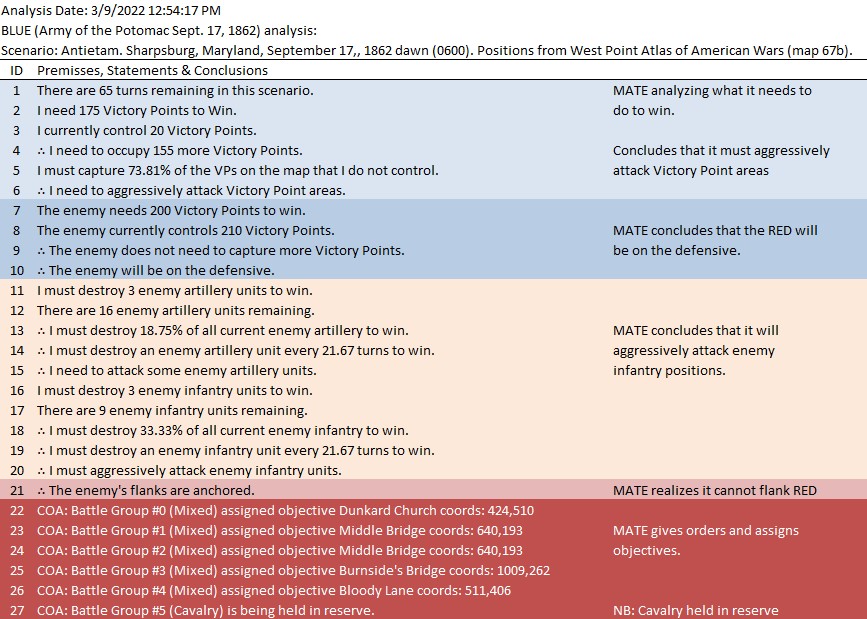
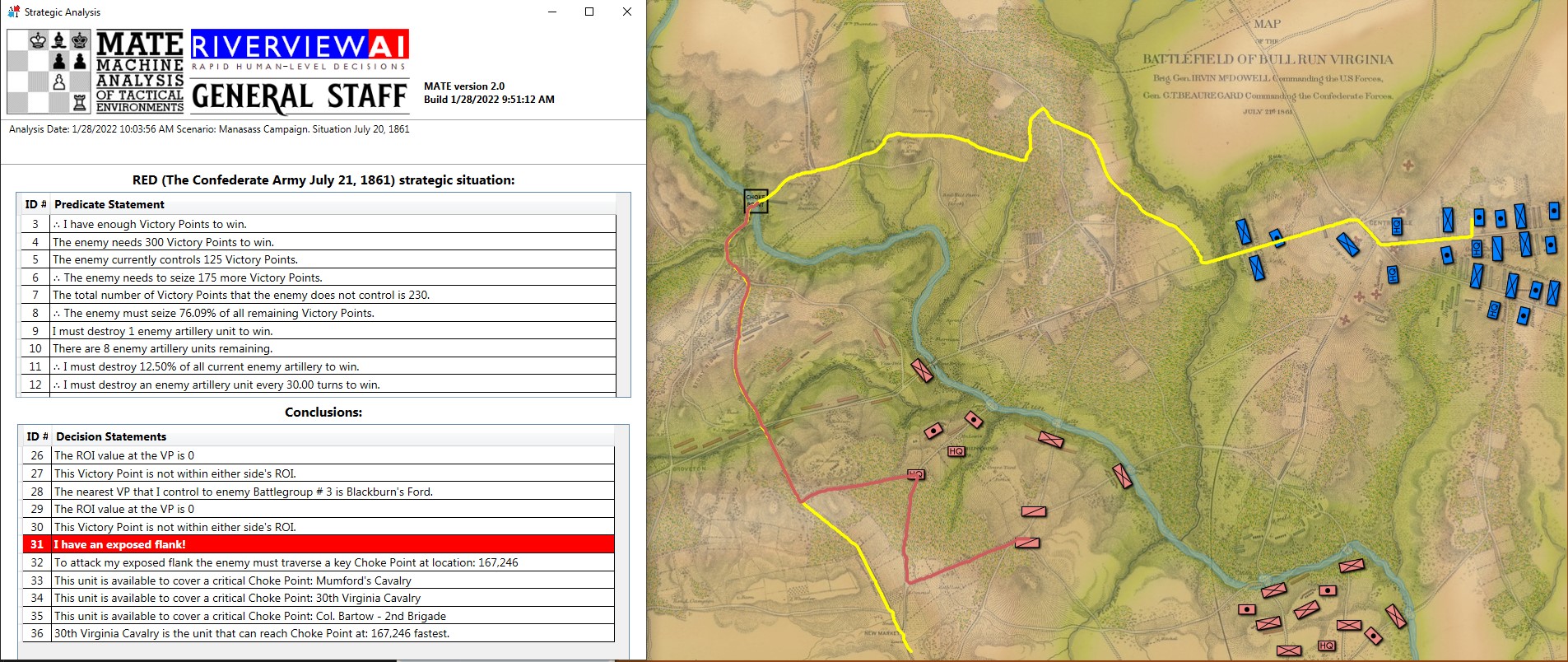
MATE AI analysis of Blue’s position. General Staff screen shot. Click to enlarge.

Text output and author’s commentary of MATE’s analysis of Blue’s position at the battle of Quatre Bras.
The salient points of MATE’s analysis of Blue (Ney’s) position at the battle of Quatre Bras are:
- Red (Wellington) has an open flank (in fact, both of Red’s flanks are exposed but MATE has calculated a left flanking maneuver is shorter than a right flanking maneuver)
- Blue has a reserve cavalry division (Line #25 in the text output above, Battle Group #3, Pire’s 2nd Cavalry Division) that is in position to spearhead the left flanking maneuver ahead of
- Battle Group #1 (the 6th Division commanded by Prince Jerome) which will follow as the main strike force of the left flanking maneuver (Line #23)
- Battle Groups #0 and #2 (Reilles and Foy’s divisions) will be the fixing force attacking Gémioncourt in the classic envelopment maneuver (see below):
- Battle Group #4 (Kellerman’s reserve cavalry division) will snatch the important crossroads at Thyle.
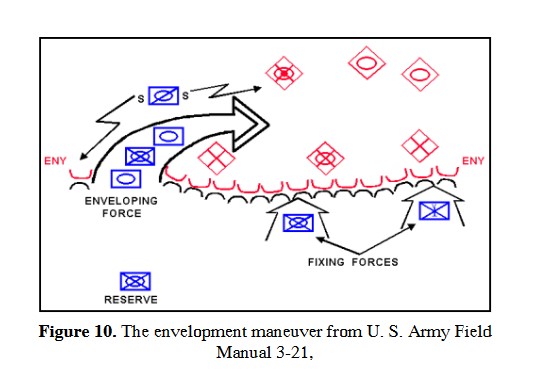
In other words, Battle Groups #3 and #1 will be the Enveloping Force and Battle Groups #0 and #2 will be the Fixing Force as illustrated in the above graphic from the U. S. Army Field Manual 3-21. Algorithms for implementing this maneuver (an early version of MATE) first appear in my paper, Implementing the Five Canonical Offensive Maneuvers in a CGF Environment.
And MATE’s new trick? It’s in line #25, above. If there is a Battle Group that is composed entirely of cavalry and horse artillery, and it is close enough, it will be used as the spearhead for the flanking maneuver.
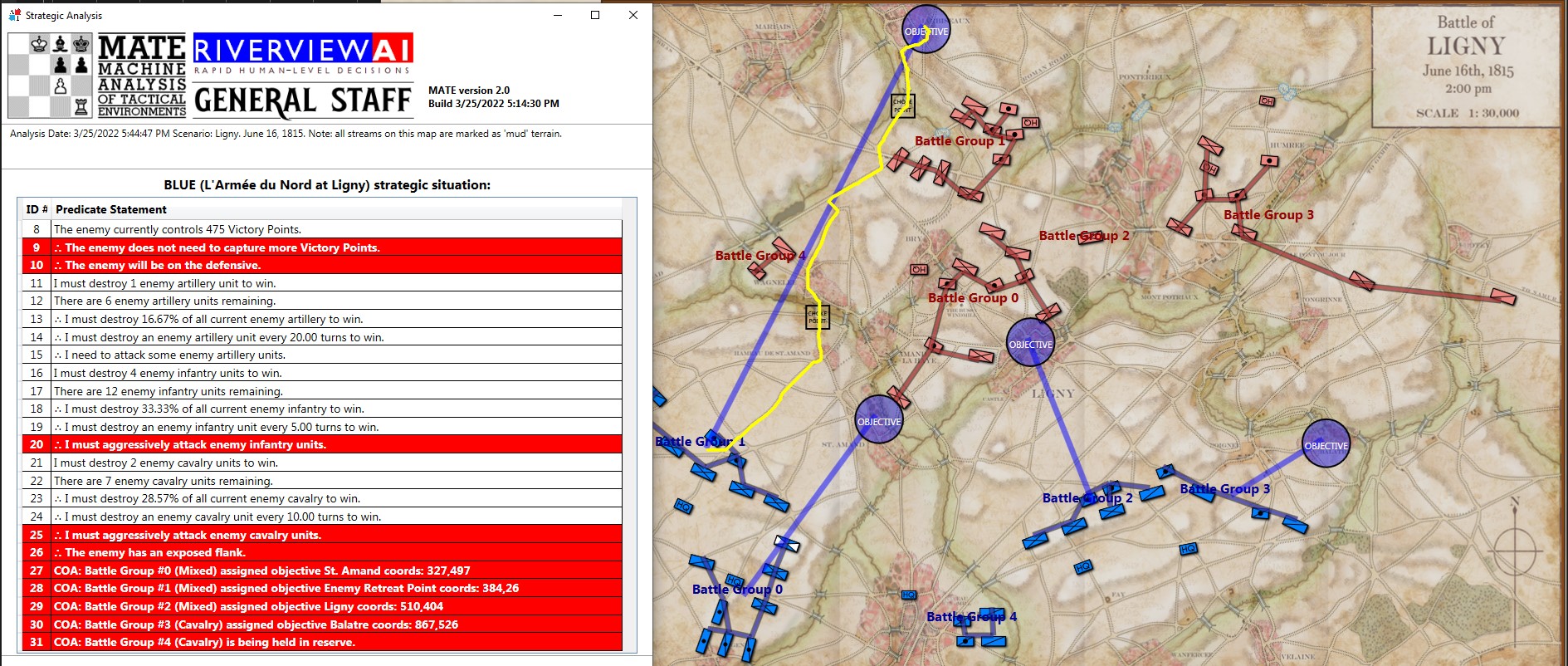
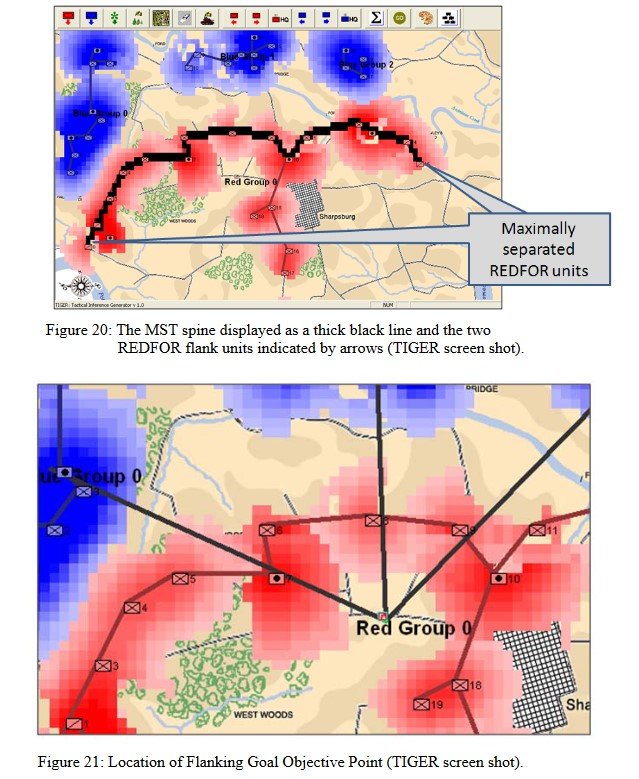
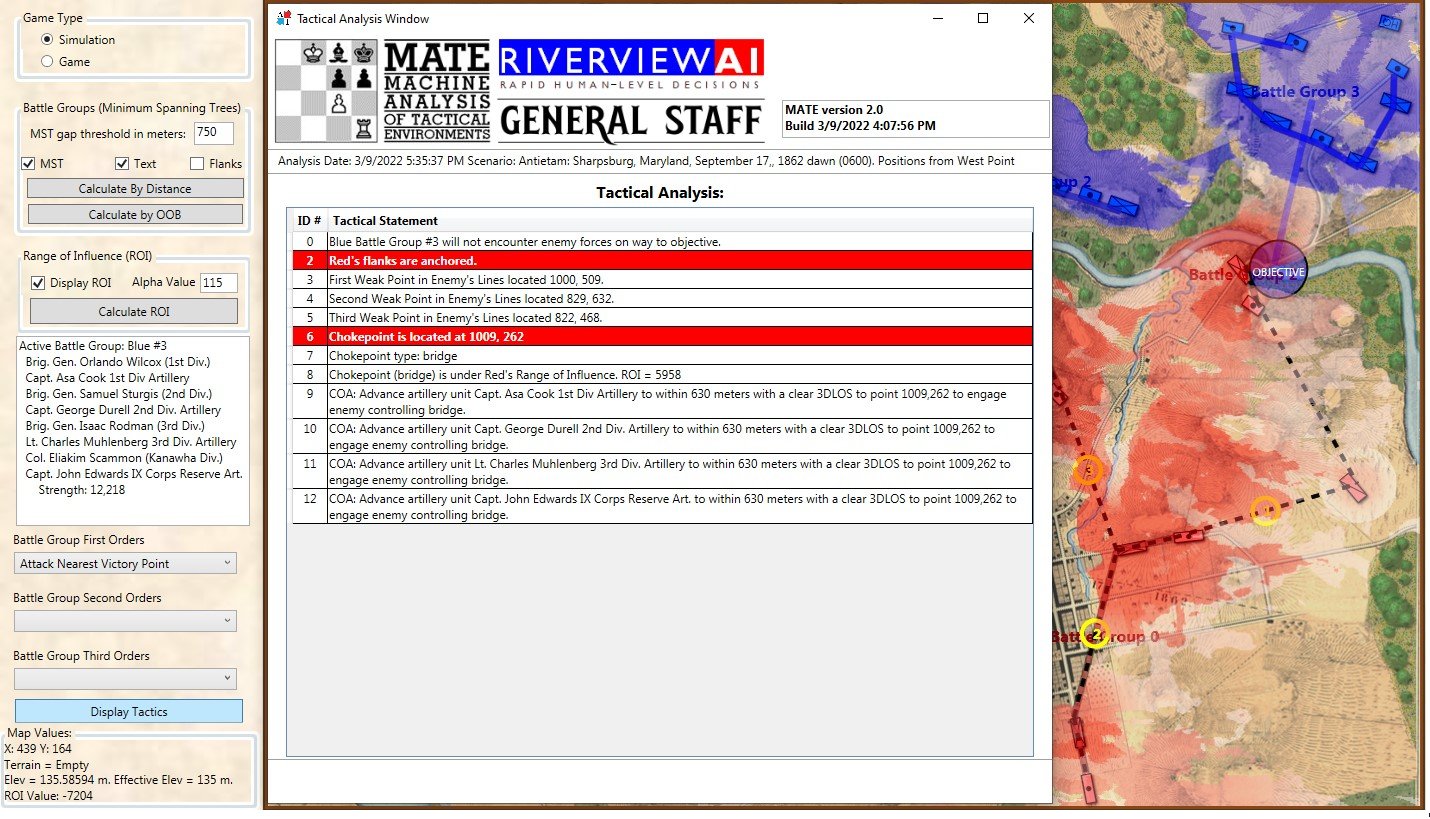
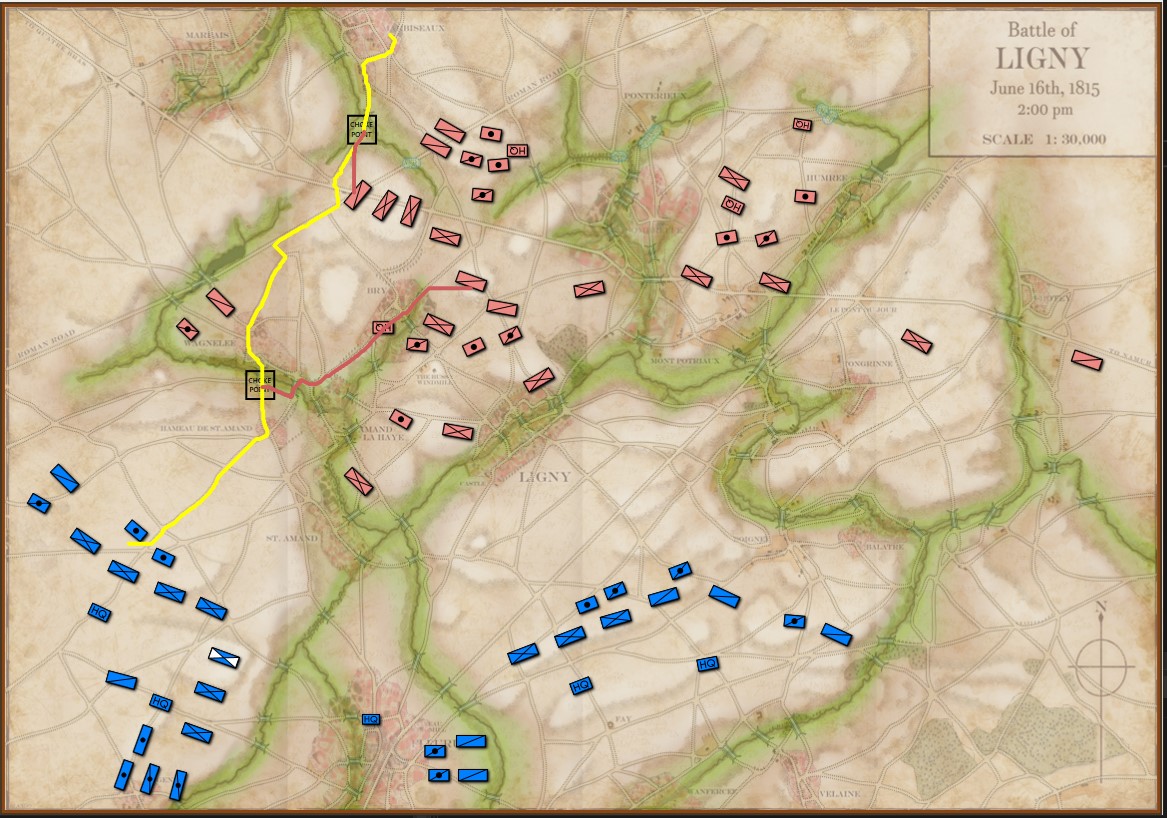
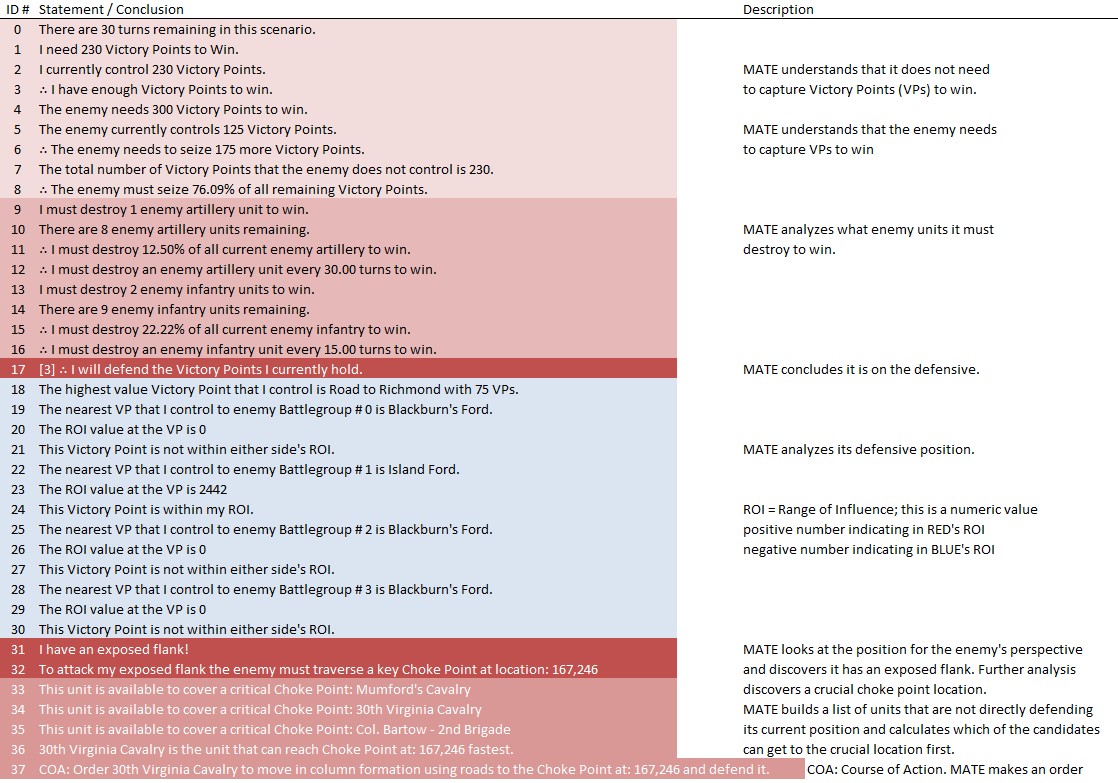
MATE’s analysis of Ligny. Screen shot from General Staff AI Editor. Click to enlarge.
But, in this situation (Ligny, above) MATE has calculated that Battle Group #1 will get to the crucial Choke Point (labeled in black, above) before the reserve cavalry Battle Group #4 will arrive and would create a tremendous bottleneck at the very choke point that MATE wants to quickly capture. Consequently, the cavalry has been left in reserve.
Mini MATE FAQ
Can MATE read and analyze any battle map from history?
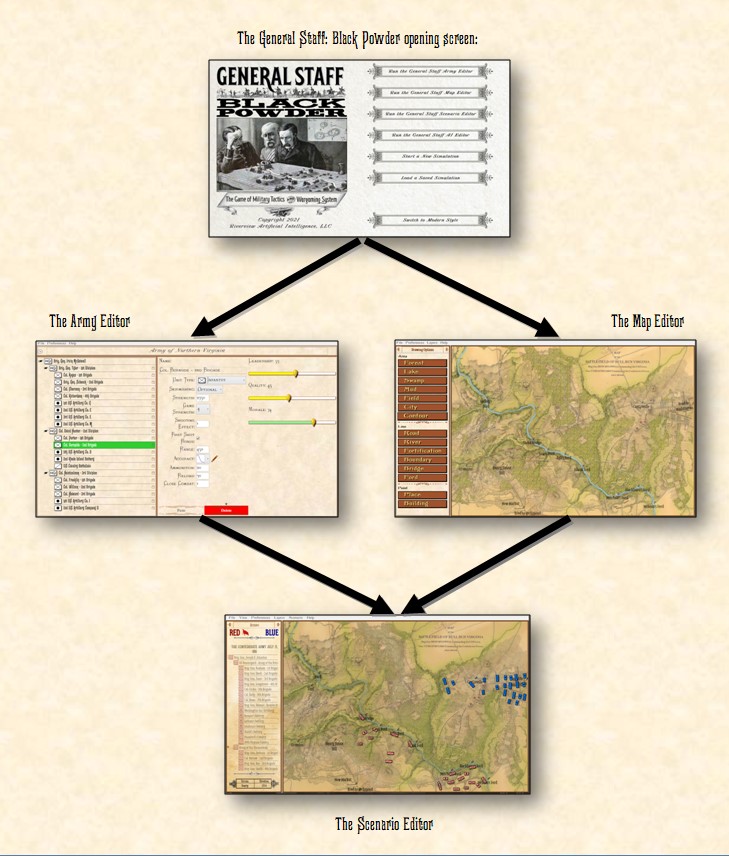
No. MATE is integrated into the General Staff Wargaming System. MATE can only ‘understand’ Order of Battle (OOB) tables created in the General Staff Army Editor, maps created in the General Staff Map Editor and scenarios created in the General Staff Scenario Editor.
What is meant by a ‘human-level’ artificial intelligence?
Perhaps you have heard of the famous Turing Test (from Alan Turing’s Computing Machinery and Intelligence). In it he describes, “The Imitation Game,” where a computer is in one room behind a closed door, and a human is another room behind a closed door. A third person, the ‘interrogator’, can only ask questions via a teletype (an ancient I/O device consisting of a keyboard and a printer) and must determine in which room the computer is and in which room is the human. In Turing’s original paper the interrogator would ask questions of the two subjects such as, “Please write me a sonnet on the subject of the Forth Bridge,” and, “Add 34957 to 70764.” Currently, no Artificial Intelligence (AI) could pass such a test; the subject area is far too broad. However, it has been my thesis, that an AI could pass such a test if the subject area is restricted to a narrow field of human endeavor, such as commanding units on a battlefield. If, in the above Turing test, the computer in one room was replaced with MATE, the human in the other room was replaced by Napoleon, and the teletype was replaced by the General Staff Wargaming System, I argue that MATE could (or soon will be able to) pass such a test (subject matter experts would not be able to discern if it was MATE or Napoleon giving orders).
Can MATE analyze current military situations?
Though MATE came out of the TIGER (Tactical Inference GenERator) project funded by DARPA, it is currently set up specifically for the General Staff: Black Powder project which limits analysis to scenarios in the 18th and 19th centuries. It is intended that this project will be followed up with General Staff: Modern Warfare to specifically work with 20th and 21st century combat.
References
| ↑1 | David Chandler, Waterloo: The Hundred Days, Macmillan Publishing Co., Inc. New York 1980, p. 85 |
|---|